
Incentivising Reasoning in LLMs: How DeepSeek Trained R1
In early 2025, DeepSeek-AI released DeepSeek-R1, the world's first open-source large language model (LLM) with reasoning capabilities to rival those of top-tier models from OpenAI and Anthropic. This triggered a huge response from the research community, the media, and even the stock market.
In this blog post, we examine the techniques used to train R1 and explore its true impact over the past six months.

What makes the DeepSeek-R1 different?
The key innovation behind DeepSeek-R1 is its reinforcement learning-first pipeline. While LLMs traditionally rely heavily on human-annotated datasets which are expensive to acquire and use RLHF as a final polishing step, R1 flips the script:
Stage 1: A brief supervised warmup on high-quality chain-of-thought examples establishes a baseline for structured reasoning.
Stage 2: The model undergoes massive-scale RL using a technique called Group Relative Policy Optimization (GRPO), rewarding correct answers and clear reasoning steps.
Stage 3: Using rejection sampling, the model generates a dataset of its best outputs to self-train via fine-tuning.
Stage 4: A final RL alignment stage teaches helpfulness, safety, and coherence across a broader range of prompts.
Stage 2 does the heavy lifting in this setup, it allowed R1 to develop emergent reasoning behaviors—such as step-by-step deduction, self-correction, and output structuring—purely from reward signals.
GRPO: Smarter RL for LLMs
Unlike standard LLM training algorithms, the key innovation of DeepSeek is GRPO, which does not require a separate critic network, drastically reducing the computational cost of training. GRPO compares groups of candidate responses and adjusts the model to prioritise the best performers based on hard-coded correctness checks (e.g. automatically checking maths problems or executing generated code). This makes GRPO more memory-efficient and scalable for large models. DeepSeek-R1 used GRPO to explore numerous solutions per prompt, evolving towards high-accuracy, human-readable reasoning chains.
Generating Data is cheaper than colleting it.
Having strong competitor models available DeepSeek used a second strategy to keep their costs of training low. They systematically prompted the most powerful closed models available to generate a high-quality but cheap dataset for supervised fine tuning.
Why it matters: Performance and practicality.
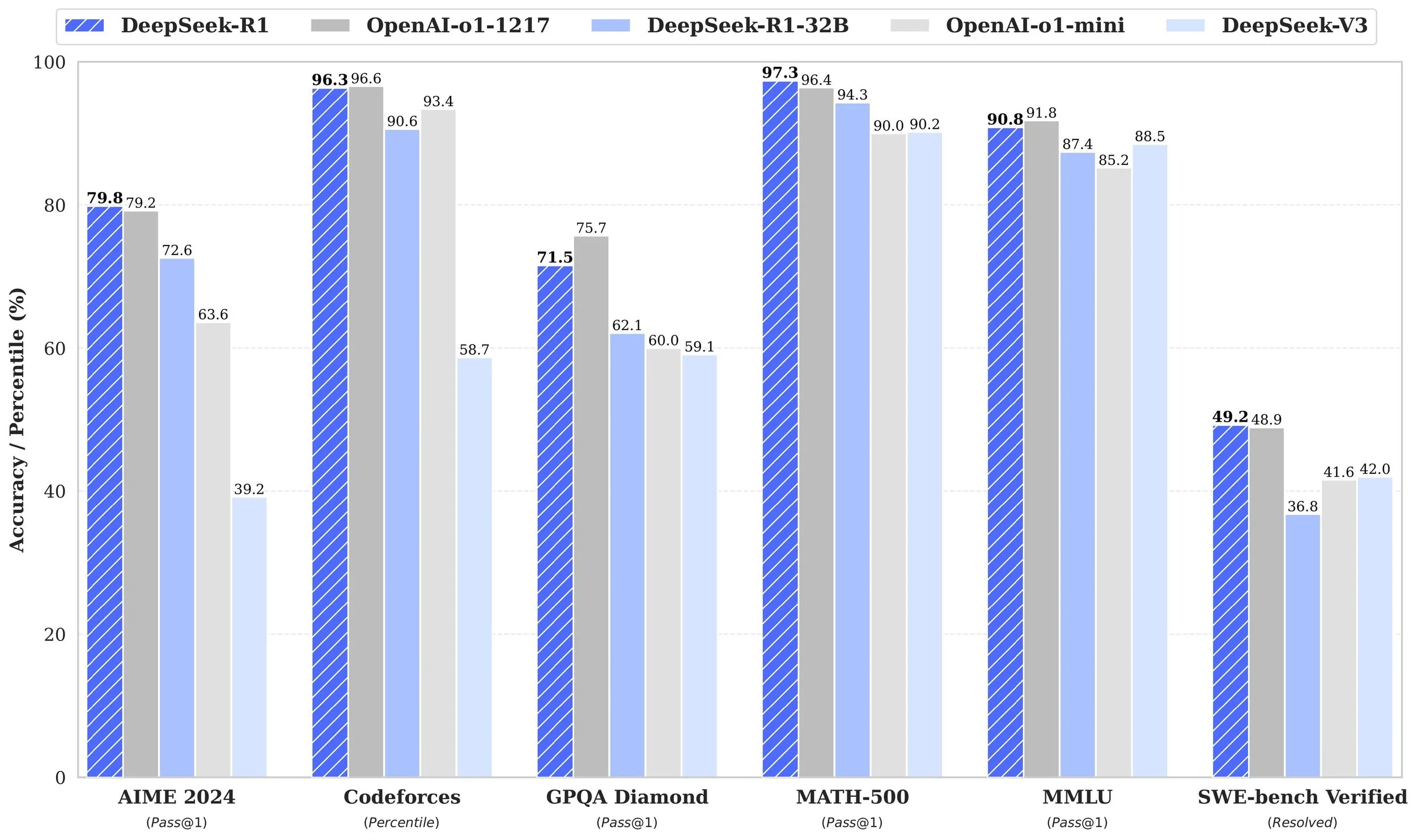
DeepSeek-R1 isn’t just a research novelty—it delivers state-of-the-art results:
Math (MATH dataset): 97.3% accuracy
AIME 2024 (Math competition): 79.8% (better than GPT-4-based baselines)
Codeforces (competitive coding): Elo 2029 (top 4% of human participants)
MMLU (knowledge benchmark): 90.8%
Reasoning & QA: Consistently top-tier on DROP, GPQA, and ARC
The model’s outputs are structured, combining detailed reasoning with clear final answers—ideal for users who value transparency and interpretability.
Final Thoughts
Through a combination of novel RL training and smart data collection DeepSeek managed to train a state of the art reasoning LLM at a fraction of the cost their competitors spent. The expanding use of intermediate tokens for its “inner monologue” by R1 reinforces the emerging insight that scaling inference compute (letting the model talk to itself for longer before giving an answer) is becoming more efficient than scaling training (training the models for longer).
Arguably the largest impact of DeepSeek-R1s release is the pressure it put on close sourced LLM vendors, like Llama did before. It quicky caused other vendors to sharply decrease prices and paywalls from their reasoning models since they were not a unique commodity anymore.
References
Shao et al. (2025), DeepSeek-R1: Incentivizing Reasoning via Reinforcement Learning
DeepSeek-AI GitHub & model documentation
Schmid, P. (2025), “How DeepSeek-R1 Was Trained” – Blog
Zhang, Y. (2025), “R1 and the Rise of RL-first LLMs” – Hugging Face Blog